
背景/场景简介
本次设计选取的是“库存系统”,可以理解为ToC场景或ToC业务中的一个子系统,从中也可以看到一些类似于零食售卖系统、网店系统、电商系统的缩影。本次实验设计主要是为了设计一个“自旋锁”来解决并发场景下“下单流程”中的库存系统的库存扣减安全性问题(防止超卖)。
本次并发实验设计的重点:
1)解决并发场景下库存扣减的安全性问题(防止超卖)。
2)提升系统接口API吞吐量/TPS。
经过测试,系统在保证安全性的前提下,系统吞吐量可以达到 970/sec~1200/sec 。

实现原理
主要是安全性的实现原理。本实验用到的“Java自旋锁” 是一个逻辑的概念,Java程序中并没有直接提供“自旋锁”,可以利用ReentrantLock或基于版本号的乐观锁改造来实现自定义“自旋锁”;数据库乐观锁指的是利用版本号+行锁来实现的一种“乐观锁”。而乐观锁的实现逻辑,也不难就是一个update语句,这里也不用自己写,MP已经实现了。
技术点: 自旋锁机制、MySQL乐观锁、线程池配置、连接池配置
乐观锁的实现原理:
版本号检查:乐观的执行更新操作,更新前对比新旧版本号,版本号一致则更新成功,利用数据库行锁/间隙锁/临键锁,即
update product set stock=quantity,version = version+1 where id = 1 and version = oldVersion;数据库表
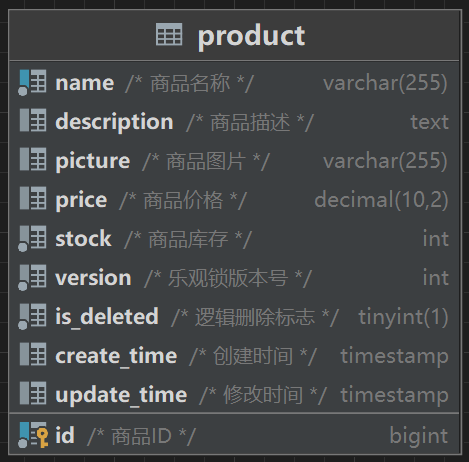
这里的更新字段不只有这2个,还有其他字段,因为不重要这里就没有写(比如 还有update_time)。
代码实现
核心逻辑
@Override
public void reduceStock(Long productId, Integer quantity) {
// 线程池线运用: 每一个请求启一个线程异步执行扣减任务
executorService.submit(() -> {
boolean success = false;
int retries = 0;
while (!success && retries < SPIN_LOCK_RETRY_TIMES) {
// 获取商品信息
Product product = productMapper.selectById(productId);
if (product != null && product.getStock() >= quantity) {
// 更新库存
product.setStock(product.getStock() - quantity);
int updateResult = productMapper.updateById(product);
if (updateResult == 1) {
success = true;// 库存扣减成功
} else {
retries++;// 更新自旋尝试次数
// 自旋等待一段时间(0.1ms)再尝试
LockSupport.parkNanos(100_000); // 100000ns <=> 0.1ms 等待时间,单位纳秒(因为CPU的时间片是纳秒级别的)
}
} else {
throw new ProductNotFoundOrReduceStockException("库存不足或商品不存在");//库存不足或商品不存在
}
}
if (!success) {
throw new ProductStockException();//库存扣减失败,请重试
}
});
}适用性分析
结论:基于数据库乐观锁实现的“自旋锁” 适用于分布式系统、单体架构系统、短任务, 然后对系统“吞吐量”要求一般,对高可用性要求一般的系统,它可以保证“库存扣减”的安全性。
吞吐量也不算低 吞吐量/TPS 1000左右,高可用也还行,一般情况也很难出现数据库单点故障的问题。
为了避免数据库单点故障问题,就需要做服务集群,而基于数据库的锁要考虑库与库之间的一致性,那么可以用Setea里的XA/TCC方案来保证一致性,但是分布式事务会缩减系统的“吞吐量”。这里就要看实际场景是否需要“高可用”,以及对“高可用”的容忍度。

虽然MySQL支持分布式架构,但本实验是偏向于“乐观锁+自旋锁”高效场景(读多写少场景),如果基于数据库的锁设计成一种“分布式锁”的方案实际上还有其他更好的方案,比如基于Zookeper/Redis的分布式锁。
后续优化
思路:进行参数调优,TODO
用静态线程池、静态数据库连接池,然后进行调优、配置。
优点:稍微简单一些,比较省事。
缺点:比较依赖于测试与监控,要经过多种测试方案和监控,拿到当前机器与系统程序的最优参数配置。还有“静态池化”的线程会一直占用系统资源。
1)线程池参数优化: 通过多方案压测与监控,得到性能稳定的参数值。
2)数据库连接池参数优化: 也可以通过多方案压测与监控,得到性能稳定的参数值。
3)JVM调优:特别是低版本的JDK,比如JDK1.8默认的参数在一般情况下就不太合适。
1) 默认“xms=1g、xmx=1g、元空间大小=256m”太小了,如果服务器是 8H16G的机器,那就可以调大一些(75%~80%, xms=10g、xmx=12g、metaspase=4g),甚至调新生代与老年代比例(原来1:2,调1:1)、更换垃圾回收器(用CMS/G1)等,这样.jar运行的时候肯定效率就会好很多。
2)JDK1.8默认的Parallel垃圾收集性能也不算最好,如果服务器是 8H16G的大内存机器,那就可以用G1,这样GC效率就高,想要短暂的STW可以用CMS,这样.jar运行的时候肯定效率就会好很多。
小结
并发问题:
自旋+睡眠 来提高成功率,每一个请求启一个线程异步执行扣减任务,3次兜底提高成功率,3次后仍然失败则抛出异常(扣减失败),失败进入下一次自旋之前先睡眠一段时间,提高成功率。
其他问题:并发量大的时候有些部分请求会失败,但并没有超卖问题。
解决方案1:在真实场景中,让前端把失败的请求重写发过来重试一遍或流程改为半同步,等待并发结果收集完之后再响应会前端。
解决方案2:用Future.get()拿结果并封装为List持久化到数据库,提供一个查询接口,让前端主动发请求来获取执行结果,针对失败的订单重新发请求走流程。
技术点
JUC知识,volatile、LockSupport、CompletableFuture<E>、TreadPoolExecutor
MP,基于版本号的乐观锁设计、自旋锁设计,本次选取MySQL作为版本号存储媒介
自定义异常、全局响应处理,统一封装后端数据并以JSON格式
Druid数据库连接池